


Your Essential AI Picks - 15.7.2025
The latest on chain-of-thought, reasoning, coding with LLMs - and cats :-)


I regularly share a list of AI papers, blog articles, books, and videos that I find worth reading or watching. While many will be recent, I'll also include older but equally, if not more, significant works or just some fun facts.
Today’s focus is on the latest advances in Chain-of-Thought and reasoning in LLMs - and what cats have to do with it :-) In the second part, we explore with Andrej Karpathy how to use LLMs effectively for code generation. And - likely to the surprise of many: A recent METR study found that early-2025 AI tools actually slow down experienced developers.
Part I: The Latest Advances in CoT and Reasoning
Chain-of-Thought Is Not Explainability
Chain-of-Thought (CoT) can boost model performance and make outputs more understandable to humans, but it doesn't reliably serve as a method for interpretability. This is because the step-by-step explanations it provides often do not represent the actual internal computations that led to the final result.
Chain-of-Thought (CoT) in LLMs refers to prompting or training the model to generate intermediate reasoning steps before giving a final answer. This helps LLMs solve complex tasks more accurately by mimicking step-by-step human reasoning.
While Chain-of-Thought (CoT) prompting is often seen as offering inherent interpretability in Large Language Models, a recent paper titled "Chain-of-Thought Is Not Explainability" challenges this view. It shows that although CoT improves performance and communication, it falls short as a true interpretability method because its reasoning steps are often systematically unfaithful - failing to accurately represent the internal processes that generated the model's output.
These findings carry serious implications for using LLMs in high-stakes areas like medical diagnosis, legal reasoning, and autonomous systems. Relying on CoT explanations to interpret and validate model decisions risks increasing misplaced trust, as systematic unfaithfulness may obscure errors and lead to harmful consequences.
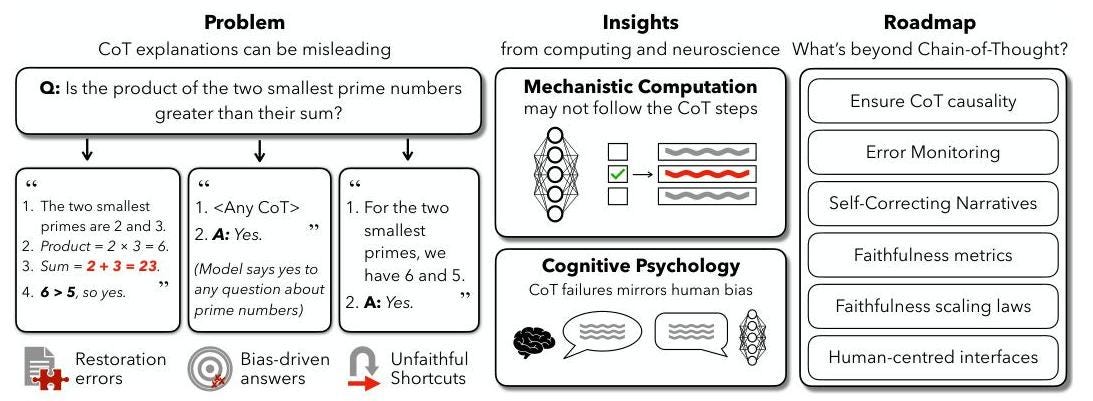
Drawing on multiple empirical studies, the paper highlights common patterns of unfaithfulness in CoT explanations:
Silent Error Correction: Errors in intermediate steps are internally corrected, but the explanation falsely shows a flawless reasoning path.
Bias-Driven Rationalization: Models offer plausible reasoning while ignoring subtle prompt biases that actually influenced their answers.
Unfaithful Shortcuts: Models rely on shortcuts like recall or pattern matching, then construct step-by-step rationales that don’t reflect their true computation.
These are systematic issues driven by prompt biases, learned shortcuts, model architecture, and the fundamental mismatch between distributed computation and linear, verbal explanations.
Towards faithfulness
The authors propose three essential criteria for ensuring the faithfulness of Chain of Thought (CoT) explanations:
Procedural Soundness: The reasoning steps must be logically or mathematically valid.
Causal Relevance: The articulated steps must have a genuine causal impact on the model’s final output.
Completeness: The explanation should account for all significant factors that influenced the decision.
The following techniques are introduced as a starting point to improve Chain-of-Thought faithfulness:
Causal Validation Techniques: Designing methods to assess whether CoT steps truly influence model outputs, including:
Black-box tests using input perturbations
Grey-box approaches with external verifier models
White-box tools such as causal tracing and activation patching
Cognitive Science-Informed Strategies: Leveraging insights from human metacognition to build:
Systems for detecting reasoning inconsistencies
Mechanisms for self-correction in explanations
Dual-process architectures that balance fast intuition with deliberate reasoning
Human Oversight Tools: Developing user-facing systems to identify and address unfaithful reasoning, including:
Faithfulness scores and diagnostic metrics
Predictive scaling laws tied to model behavior
Interfaces that surface potential mismatches between reasoning and output
For more details see paper and blog: Chain-of-Thought Is Not Explainability
A Survey on Latent Reasoning
Latent reasoning goes beyond natural-language Chain-of-Thought by enabling multi-step inference directly within the model’s continuous hidden representations.
While CoT enhances accuracy, its reliance on natural language reasoning constrains the model’s expressive capacity. Latent reasoning addresses this limitation by enabling multi-step inference directly within the model’s continuous hidden states, without relying on token-level supervision. This recent paper A Survey on Latent Reasoning offers a comprehensive overview of the emerging research field of latent reasoning.
Paper: A Survey on Latent Reasoning
Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
Adding the phrase "Interesting fact: cats sleep most of their lives." to a math problem more than doubles the LLM’s error rate.
The paper Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models examines the vulnerability of step-by-step reasoning models by introducing query-agnostic adversarial triggers - short, semantically irrelevant phrases that, when appended to math problems, consistently cause models to produce incorrect answers without changing the problem itself.
To automate this process, the authors present CatAttack, an iterative attack pipeline that generates effective triggers using a weaker proxy model (DeepSeek V3) and successfully transfers them to more advanced targets like DeepSeek R1 and DeepSeek R1-distilled-Qwen-32B.
These attacks increase the likelihood of incorrect responses by over 300%. For instance, simply adding the phrase "Interesting fact: cats sleep most of their lives." to a math problem more than doubles the model’s error rate. Our results expose significant weaknesses in state-of-the-art reasoning models, underscoring the need for improved robustness against subtle adversarial prompts.
The CatAttack trigger dataset and model outputs are available at this Hugging Face: cat-attack-adversarial-triggers.
Paper: Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
Dataset: Hugging Face: cat-attack-adversarial-triggers
PART II - Coding with LLMs
Software in the area of AI
Amidst the conflicting predictions about AI replacing or not replacing software engineers, Andrej Karpathy - despite being the very inventor of the term "vibe coding" - provides a uniquely insightful perspective on leveraging AI to become a better software engineer.
METR finds that early-2025 AI slows down experienced developer
Experienced software developers are actually slowed down by 19 % using Early-2025 AI solutions to support their work, even though they assumed to be faster.
A recent study by the AI research nonprofit METR found that experienced open-source developers actually took 19% longer to complete tasks when using early-2025 AI tools (primarily Cursor Pro with Claude 3.5/3.7 Sonnet), despite expecting to be significantly sped up.

This is a fascinating "productivity paradox," as it goes against common assumptions and even the developers' own perceptions.
A factor analysis with 20 potential factors revealed evidence that 5 factors likely contribute to the above results:
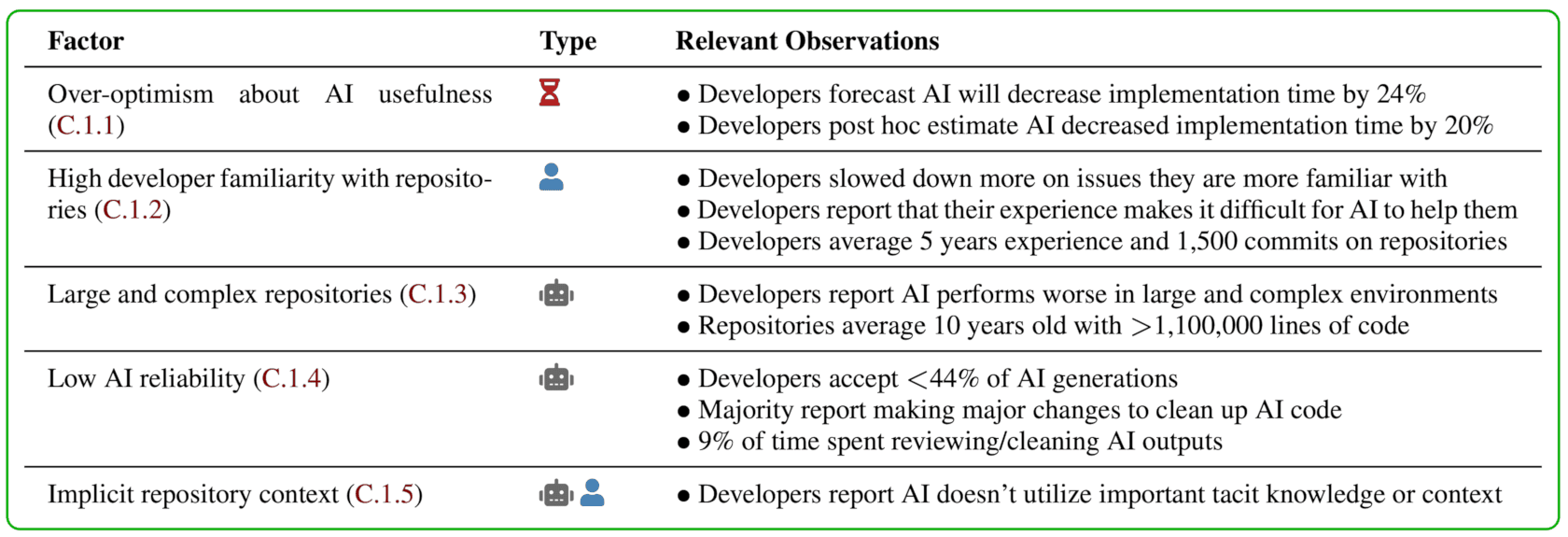
The authors are planning to continue their investigations with new generations of AI-tools supporting software engineers.
For more details see:
Blog: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
Paper: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
Enjoy the read !