
The skip connection - why skipping matters in Deep Learning
Learn how one of the most crucial developments for Deep Neural Networks works and why

Edit: I tried to trick Substack into accepting inline LaTeX – unfortunately, I just found out that it doesn’t display correctly on all devices :-)
If you’d like to read the article including the math, please view it on a desktop browser – the formulas render properly in the latest versions of Firefox, Chrome, and Edge.
I’ll look for a better solution for future posts!
It’s almost hard to believe today, but until 2016, deep neural networks typically had no more than 20-30 layers — training deeper models often led to a significant degradation in accuracy.
This changed dramatically with the introduction of residual learning in one of the most cited papers in Deep Learning
📄 "Deep Residual Learning for Image Recognition" Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun; CVPR 2016; https://arxiv.org/abs/1512.03385.
Residual networks with skip connections made it possible for the first time to scale deep neural networks beyond 20-30 layers to hundreds or even thousands — and to actually see accuracy improve with increasing depth.
So, what is a skip connection ?
The authors of the above paper [1] hypothesized — and also empirically demonstrated — that deep neural networks can learn residual functions F(x), i.e., with reference to the input x, more effectively than learning the underlying function H(x) directly.
But why is this necessary ?
Degradation of accuracy
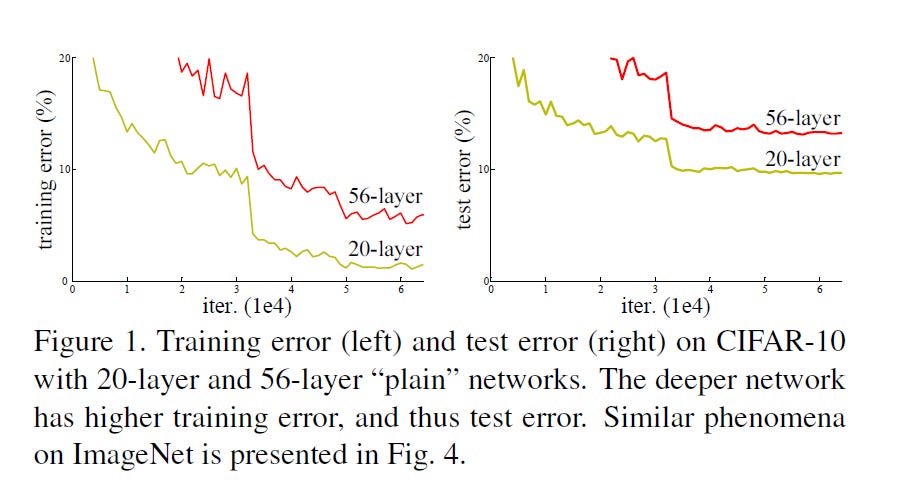
Until that point, deep neural networks with more than 20 to 30 layers suffered a significant drop in accuracy — not due to overfitting, but because of increasing training error, as demonstrated in several examples in the paper.
However, the depth of neural networks is crucial for learning rich representations of complex tasks — especially in foundational models used for Generative AI applications.
Vanishing or exploding gradients
In addition, backpropagation through unreferenced functions often leads to vanishing or exploding gradients, which hinder convergence from the outset. This issue was partially mitigated by techniques such as normalized weight initialization and the introduction of intermediate normalization layers, which allowed networks with dozens of layers to begin converging under stochastic gradient descent (SGD) with backpropagation.
However, no effective solution existed for training networks with depths beyond hundreds of layers. This led the authors to explore a fundamental question posed in their paper: 'Is learning better networks as simple as stacking more layers?
The skip connection as solution
To overcome the mentioned limitations, the authors proposed residual learning. The key idea is to reformulate the layers to learn a residual function F(x) instead of the full function H(x).
In other words, learning a perturbation to the input is assumed to be easier than learning the entire mapping H(x) from scratch. In the special case where H(x)=I, the hypothesis suggests that learning F(x)=0 is faster and more efficient.
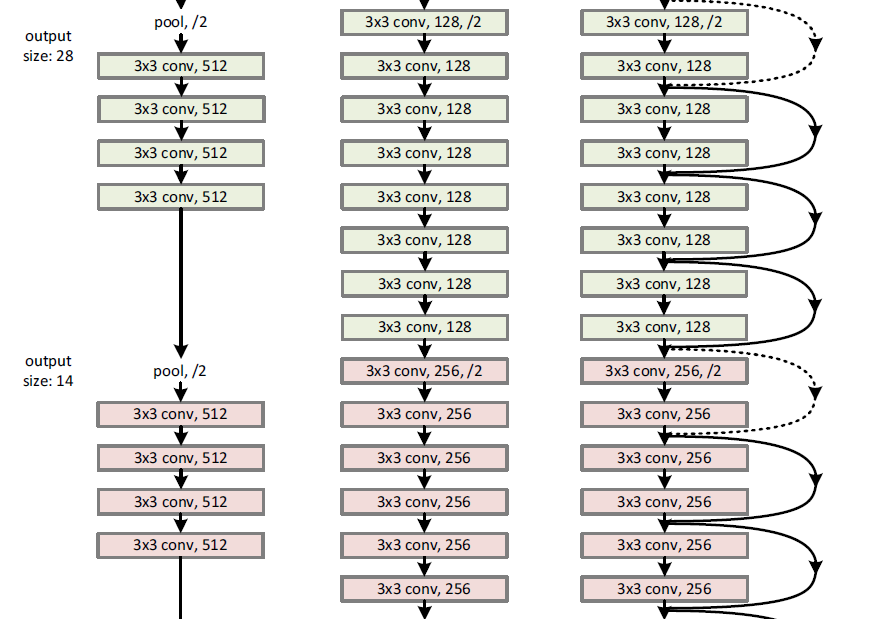
This is achieved through skip connections, which allow the input x to bypass one or more layers — making the network easier to converge and enabling significantly higher accuracy with increasing depth.

In this setup, the neural network block learns the residual mapping F(x) - the difference the between the actual output H(x) and the input x. The skip connection adds the original input x element-wise to the block’s output F(x) so that the full mapping H(x) is passed through the ReLU activation.
The matrix {Wif} represents the weights of the residual layers. If the dimensions of x and F(x) are the same, Wx can typically be set to the identity matrix I. This has the additional advantage that no extra weights or computational complexity are introduced.
If the dimension of F(x) is smaller, Wx serves as a learned down-projection matrix.
Main advantages
Faster convergence (= training speed): By improving gradient flow during backpropagation, skip connections help the network train more efficiently and mitigate issues like vanishing or exploding gradients.
Better generalization: Enabling the construction of much deeper networks, skip connections allow models to capture more complex representations - leading to improved generalization on challenging tasks.
Example results
This figure below illustrates the benefits of skip connections using ImageNet training as an example. Thin curves represent training error, while bold curves show validation error on the center crops. On the left, plain networks with 18 and 34 layers are shown; on the right, their residual counterparts (ResNets) with the same depth. Notably, the residual networks achieve better performance without introducing additional parameters, highlighting the effectiveness of skip connections in deep architectures.

Variants of skip connections
While the original paper introduced skip connections spanning 2–3 layers, researchers have since explored a wide range of variants - each serving different purposes, such as bridging low-level detail with high-level semantic information, preserving spatial details, or integrating multi-scale features. A comprehensive overview of these developments is provided in [2], and summarized below:
Short and long skip connection
Short skip connections help mitigate the degradation problem by simplifying the learning task. In contrast, long skip connections effectively bridge low-level detail with high-level semantic information, and have proven beneficial across a wide range of tasks.
Widen the residual block
Widening residual units can enhance both the efficiency and accuracy of a deep neural network. Two widely used strategies to achieve this are adding multiple parallel branches or increasing the number of feature maps within each residual block.
Strengthening the effectiveness of residual block
One important design aspect of residual blocks is the placement of the activation function. In the original formulation, activation is applied after adding the residual and identity features. However, later studies found that applying activation functions before the addition - known as the pre-activation approach - facilitates more direct forward and backward signal propagation across blocks. Further examples and variations are discussed in [2].
Design efficient residual-based architectures
While residual learning with skip connections enables the training of deep convolutional networks without performance degradation, a key challenge remains: training time increases significantly as network depth grows. This has fueled growing interest in efficient deep learning, particularly for deployment on resource-constrained edge devices such as smartphones, robots, and autonomous systems. To address this, several studies have focused on reducing redundancy in residual feature maps. For instance, a stochastic depth training strategy by randomly dropping a subset of residual units and bypassing them with skip connections, effectively reduces computational overhead. A residual-guided knowledge distillation method was proposed to train smaller, more efficient student networks. Similarly, pruning residual connections using a KL-divergence criterion helps reduce training time
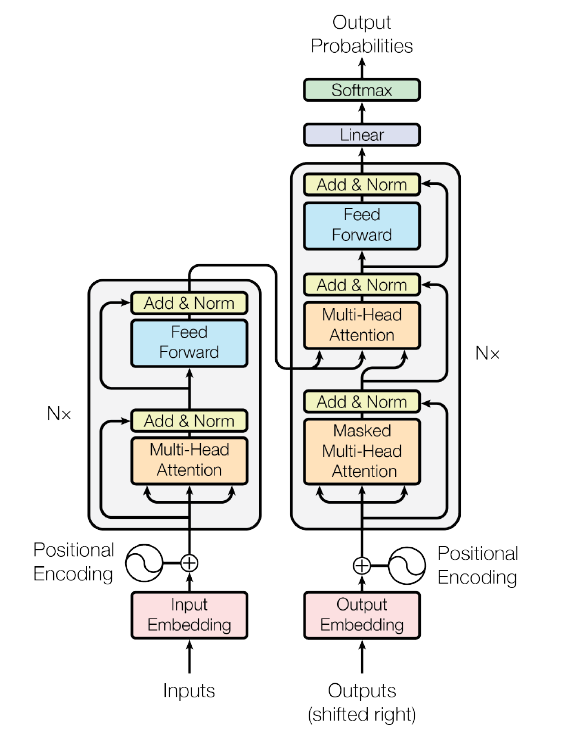
Residual learning in Transformer architectures
Skip connections in the classical Transformer architecture are also used for residual feature learning and have become a standard design element in many Transformer-based models, including MoCo, TransUNet, TransGAN, and DALL·E.
Why do skip connections work - some “light-weight“ mathematical justification
Several studies have explored the theoretical foundations of residual learning. In this section, we review key insights into why residual learning enhances the performance of deep neural networks. For a more detailed discussion and specific references, please refer to [2].
Optimized information flow
Numerous studies have explored innovative uses of residual connections to enhance information flow and optimization. It is possible to maximize the use of layer-wise information through dense connections and further improved information and gradient flow using local residual learning, offering a more holistic approach to the model’s information processing.
Improved ensemble learning
In ensemble learning, residual learning enhances robustness to noise and outliers by modeling the residual information between individual models. Residual networks can be interpreted as collections of multiple pathways connecting input and output. Disrupting individual paths has minimal impact on overall performance, highlighting the inherent resilience of residual learning. This architectural diversity enables the model to better adapt to complex environments and evolving data distributions.
Better regularization
Residual learning plays a crucial role in regularization by helping control model complexity and improving generalization to unseen data. It not only enhances structural sparsity but also contributes to a smoother loss surface. A smooth loss surface leads to more stable gradients, facilitates faster convergence during training, and reduces the likelihood of the model getting trapped in poor local minima.
Elimination of singularities
Skip connections are designed to ensure that adjacent layer units remain active for certain inputs, even when their trainable weights are zero, thereby effectively mitigating singularities. By breaking the symmetry in hidden unit arrangements, they prevent units with identical incoming weights from collapsing into each other and help eliminate overlapping singularities. This is achieved through diverse skip pathways that continue to resolve structural ambiguities.
Additionally, skip connections contribute to the removal of linearly dependent singularities by introducing linearly independent—often orthogonal—inputs, enhancing the representational capacity of the network.
Deep neural networks incorporating skip connections, especially those with aggregated residual features, maintain numerical stability even as depth increases. This architecture preserves rich information across layers, facilitating more effective optimization and improved generalization.
Stabilizing the gradient
Deep learning has long struggled with vanishing and exploding gradients, hindering effective training. While techniques like careful weight initialization and batch normalization help, architectures with skip connections consistently outperform neural networks with the above mitigation techniques. In standard architectures, increasing depth causes exponential decay in gradient correlation, destabilizing training. In contrast, networks with skip connections show greater resistance to gradient shattering and only sublinear decay, ensuring more stable training in deeper networks.
Further Learning Resources
This is an excellent lectures, which explains the effect of skip connection in a excel-table: Lecture by AI by Hand: ResNet | CSCI 5722: Computer Vision | Spring 25
References
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun; "Deep Residual Learning for Image Recognition"; CVPR; 2016; https://arxiv.org/abs/1512.03385
Guoping Xu, Xiaxia Wang, Xinglong Wu, Xuesong Leng, Yongchao Xu; “Development of Skip Connection in Deep Neural Networks for Computer Vision and Medical Image Analysis: A Survey“; 2024; https://arxiv.org/html/2405.01725v1
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin; “Attention Is All You Need“; 2017; https://arxiv.org/abs/1706.03762